
What is AWS EFS?
EFS stands for ElasticFileSystem and it is the AWS implementation of a network drive.
The drive can be almost one click created in the AWS Console and it takes several minutes to boot up and generate the URL.
For more details please refer to AWS ElasticFileSystem page.
EFS burstable performance
EFS does have the specified in creation size and this size dictates how much data it can process per second.
in other words EFS size is bound with the throughput it can provide.
This is caused by the Burst Credits. Since EFS is a burstable volume(similar to t2 family in EC2), working below the throughput provided by the corresponding volume size, generates burst credits. Workloads above this provided limit consumes generated credits.
EFS scaling
As noted above, EFS can scale depending on the total size of the data stored on it. Basically, more data means more speeds and less trouble.
This table represents roughly how does an EFS drive when files increase in size:
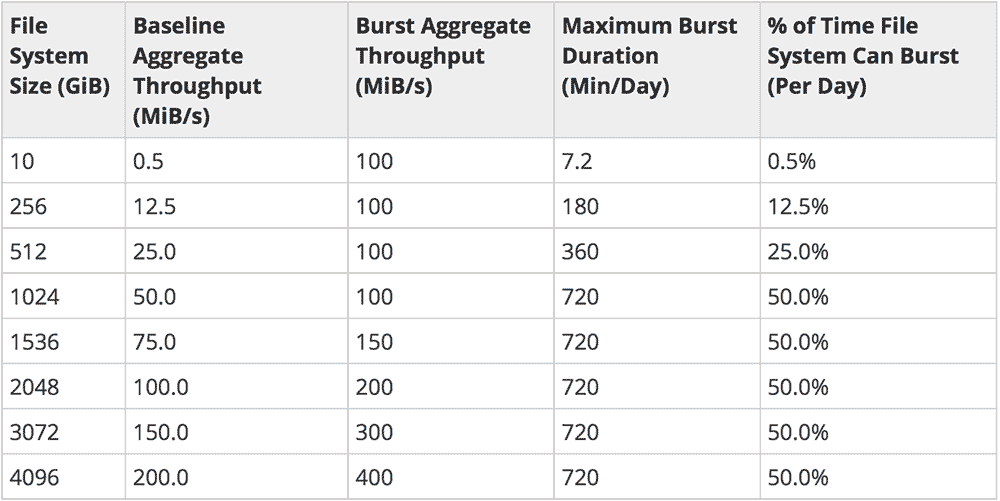
Following this chart your company can estimate how much data must be on the drive to get the performance that your app(s) require to work seamlessly.
The problem
The problem is that if this provided limit is not enough to cover the usual workflow for your application, eventually all credits are going to run out and
you will face crippling speeds from the volume that can result in timeouts.
Here comes the second problem – is there a way to scale BEFORE it is already an issue.
And the answer is yes.
Solution
When creating the drive, you set the starting size of the volume, that does not mean it cannot expand when needed and this causes the boost in throughput.
So if you upload some files to the drive with the sole purpose of just boosting the size and the speeds this might work. Instead of looking for a big enough file to upload you can just create one.
In Linux there are several (quite a lot) ways to “generate” a file. Dummy files are used in many scenarios and this is one of them.
So let’s say i want to create a 100GB file and expand my drive and boost my credits and performance. Here is a possible command:
$ truncate -s 100G /path/to/efs/.bigfile
This command will create the invisible file .bigfile with the size of 100 GB and therefore will expand the drive.
Well, turns out it will not.
According to AWS support, “truncate -s” only created a sparse file on the EFS share. Whilst this does indeed show up as 100GB in with the ls -lah, the output from df shows the true on-disk size, which matches the metered size of the EFS share. Sparse files do not count towards baseline performance.
So the option that they suggested is the dd command. An example command to create a 100GiB file will use “dd” and source data from /dev/zero:
$ dd if=/dev/zero of=/path/to/efs/dummyfile bs=1M count=100000
When checked in df it may not appear right away since AWS collects this data in specific intervals. If you need a different size value from the ones in the table above, you can refer to AWS ElasticFileSystem Performance page.